These days, I met several scenarios that have some database principles and common concepts. While most of them I have already forgot. As a computer science background student, it really makes me ashamed.
So, here I put them as more as I could consider.
[TOC]
关系型数据库 RDBMS
1. Common Concepts
1.1 Transactions (事务)
A transaction symbolizes a unit of work performed within a database management system (or similar system) against a database, it’s a single unit of logic or work, sometimes made up of multiple operations.
A database transaction, by definition, must follow ACID principle, witch is atomic, consistent, isolated and durable.
MySQL 事物处理的两种主要方法
- 用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
- 直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
1.2 DML vs DDL vs DCL vs TCL
- DDL is short name of Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database.
CREATE– to create database and its objects like (table, index, views, store procedure, function and triggers)ALTER– alters the structure of the existing databaseDROP– delete objects from the databaseTRUNCATE– remove all records from a table, including all spaces allocated for the records are removedCOMMENT– add comments to the data dictionaryRENAME– rename an object
- DML is short name of Data Manipulation Language which deals with data manipulation, and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE etc, and it is used to store, modify, retrieve, delete and update data in database.
SELECT– retrieve data from the a databaseINSERT– insert data into a tableUPDATE– updates existing data within a tableDELETE– Delete all records from a database tableMERGE– UPSERT operation (insert or update)CALL– call a PL/SQL or Java subprogramEXPLAIN PLAN– interpretation of the data access pathLOCK TABLE– concurrency Control
-
DCL is short name of Data Control Language which includes commands such as GRANT, and mostly concerned with rights, permissions and other controls of the database system.
GRANT– allow users access privileges to databaseREVOKE– withdraw users access privileges given by using the GRANT command
- TCL is short name of Transaction Control Language which deals with transaction within a database.
COMMIT– commits a TransactionROLLBACK– rollback a transaction in case of any error occursSAVEPOINT– to rollback the transaction making points within groupsSET TRANSACTION– specify characteristics for the transaction
1.3 Data Warehouse
ETL
2. Principles
2.1 ACID
在关系型数据库管理系统(DBMS)中事务具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)
-
原子性
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性
在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
-
隔离性
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
目前主要有两种方式实现ACID:第一种是Write ahead logging,也就是日志式的方式。第二种是Shadow paging。
2.2 范式 Normal Forms
-
基础概念:
-
函数依赖(Function Dependency):如果在一张表中,在属性(或属性组)$X$的值确定的情况下,必定能确定属性 $Y$的值,那么就可以说 $Y$函数依赖于 $X$,写作$X \to Y$。
-
完全函数依赖: 在一张表中,若 $X \to Y$,且对于 $X$ 的任何一个真子集$X’$(假如属性组 X 包含超过一个属性的话),$X ‘ \to Y$ 不成立,那么我们称 $Y$ 对于 $X$ 完全函数依赖,记作
 。
。 -
部分函数依赖:假如 Y 函数依赖于 $X$,但同时 $Y$ 并不完全函数依赖于 $X$,那么我们就称 Y 部分函数依赖于 $X$,记作。

-
传递函数依赖:假如 $Z$ 函数依赖于$Y$,且 $Y$ 函数依赖于 $X$ ,$Y$ 不包含于 $X$,且 $X$ 不函数依赖于 $Y$,那么我们就称 $Z$ 传递函数依赖于 $X$ ,记作
 。
。 -
多值依赖(Multi-valued Dependency):在一张表中,如果属性X的值可以决定其他属性的一组值,那么属性$X$和他可以决定的值之间就存在多值依赖。
多值依赖具有对称性和传递性。函数依赖可以看作多值依赖的一种特殊情况。
-
连接依赖(Join Dependency):如果一张表$T$总是可以通过多张表的
join操作创建,那么表$T$就服从连接依赖,其中多张表都包含$T$的属性的子集。
-
-
第一范式(1NF) —— 属性不可再分
关系型数据库必须满足第一范式。第一范式是对属性的原子性约束,要求属性具有原子性,不可再分解。
-
第二范式(2NF)
在第一范式基础上,一张表中的属性之间不存在部分函数依赖。
-
第三范式(3NF)
在第二范式基础之上,一张表中的属性之间不存的传递函数依赖。
-
BCNF
通常认为BCNF是修正的第三范式,有时也称为扩充的第三范式。BCNF需要满足条件:
-
所有非主属性对每一个候选键都是完全函数依赖
-
所有的主属性对每一个不包含它的候选键,也是完全函数依赖
-
没有任何属性完全函数依赖于非候选键的任何一组属性
-
-
第四范式(4NF):
满足3NF,消除表中的非平凡且非函数依赖的多值依赖
一般情况下,数据库设计满足三范式就可以,甚至为了在十分复杂的数据库里为了提升效率,要做到逆范式。
在结构规范化、减少数据冗余和提高数据库访问性能之间仔细权衡,适当折中。
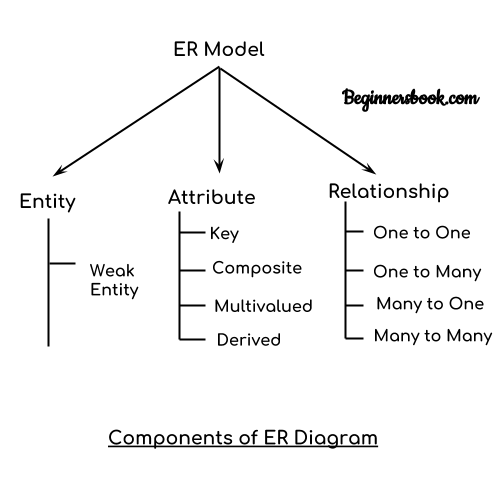
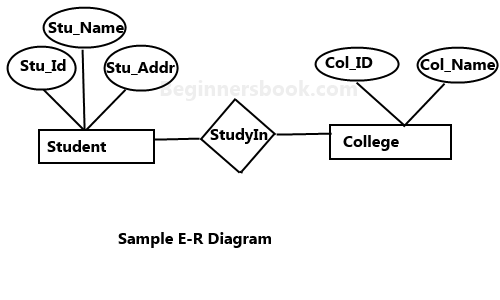
2.3 ER图
通常我们可以通过ER图进行数据库模型设计
NoSQL(Not Only SQL)
There are three cornerstones of the existing of NoSQL, which is CAP, BASE and Eventual Consistency. While 5-min principle shows the theoretical basis of memory data.
CAP
-
C: Consitency
-
A: Availability
-
P: Tolerent of network Partition
10年前,Eric Brewer教授指出了著名的CAP理论,后来Seth Gilbert 和 Nancy lynch两人证明了CAP理论的正确性。CAP理论告诉我们,一个分布式系统不可能满足一致性,可用性和分区容错性这三个需求,最多只能同时满足两个。 熊掌与鱼不可兼得也。关注的是一致性,那么您就需要处理因为系统不可用而导致的写操作失败的情况,而如果您关注的是可用性,那么您应该知道系统的read操作可能不能精确的读取到write操作写入的最新值。因此系统的关注点不同,相应的采用的策略也是不一样的,只有真正的理解了系统的需求,才有可能利用好CAP理论。 作为架构师,一般有两个方向来利用CAP理论 key-value存储,如Amaze Dynamo等,可根据CAP三原则灵活选择不同倾向的数据库产品。 领域模型 + 分布式缓存 + 存储 (Qi4j和NoSql运动),可根据CAP三原则结合自己项目定制灵活的分布式方案,难度高。 而对大型网站,可用性与分区容忍性优先级要高于数据一致性,一般会尽量朝着 A、P 的方向设计,然后通过其它手段保证对于一致性的商务需求。架构设计师不要精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。 不同数据对于一致性的要求是不同的。举例来讲,用户评论对不一致是不敏感的,可以容忍相对较长时间的不一致,这种不一致并不会影响交易和用户体验。而产品价格数据则是非常敏感的,通常不能容忍超过10秒的价格不一致。
Eventual Consistency
一言蔽之:过程松,结果紧,最终结果必须保持一致性 为了更好的描述客户端一致性,我们通过以下的场景来进行,这个场景中包括三个组成部分: 存储系统 存储系统可以理解为一个黑盒子,它为我们提供了可用性和持久性的保证。 Process A, B, C, 相互独立, 同时实现对存储系统的write和read操作。 下面以上面的场景来描述下不同程度的一致性:
-
强一致性(即时一致性)
假如A先写入了一个值到存储系统,存储系统保证后续A,B,C的读取操作都将返回最新值
-
弱一致性
假如A先写入了一个值到存储系统,存储系统不能保证后续A,B,C的读取操作能读取到最新值。此种情况下有一个“不一致性窗口”的概念,它特指从A写入值,到后续操作A,B,C读取到最新值这一段时间。
-
最终一致性 最终一致性是弱一致性的一种特例。假如A首先write了一个值到存储系统,存储系统保证如果在A,B,C后续读取之前没有其它写操作更新同样的值的话,最终所有的读取操作都会读取到最A写入的最新值。此种情况下,如果没有失败发生的话,“不一致性窗口”的大小依赖于以下的几个因素:交互延迟,系统的负载,以及复制技术中replica的个数(这个可以理解为master/salve模式中,salve的个数),最终一致性方面最出名的系统可以说是DNS系统,当更新一个域名的IP以后,根据配置策略以及缓存控制策略的不同,最终所有的客户都会看到最新的值。
-
Causal consistency(因果一致性)
如果Process A通知Process B它已经更新了数据,那么Process B的后续读取操作则读取A写入的最新值,而与A没有因果关系的C则可以最终一致性。
-
Read-your-writes consistency
如果Process A写入了最新的值,那么Process A的后续操作都会读取到最新值。但是其它用户可能要过一会才可以看到。
-
Session consistency
此种一致性要求客户端和存储系统交互的整个会话阶段保证Read-your-writes consistency.Hibernate的session提供的一致性保证就属于此种一致性。
-
Monotonic read consistency
此种一致性要求如果Process A已经读取了对象的某个值,那么后续操作将不会读取到更早的值。
-
Monotonic write consistency
此种一致性保证系统会序列化执行一个Process中的所有写操作。
BASE
- Basically Availble –基本可用
-
Soft-state –软状态/柔性事务
“Soft state” 可以理解为”无连接”的, 而 “Hard state” 是”面向连接”的
- Eventual Consistency –最终一致性
最终一致性, 也是是 ACID 的最终目的。
BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性,获得可用性或可靠性:
Basically Available基本可用。支持分区失败(e.g. sharding碎片划分数据库)
Soft state软状态 状态可以有一段时间不同步,异步。
Eventually consistent最终一致,最终数据是一致的就可以了,而不是时时一致。
BASE思想的主要实现有
-
按功能划分数据库
-
sharding碎片
BASE思想主要强调基本的可用性,如果你需要高可用性,也就是纯粹的高性能,那么就要以一致性或容错性为牺牲,BASE思想的方案在性能上还是有潜力可挖的。
I/O的五分钟法则
在 1987 年,Jim Gray 与 Gianfranco Putzolu 发表了这个”五分钟法则“的观点,简而言之,如果一条记录频繁被访问,就应该放到内存里,否则的话就应该待在硬盘上按需要再访问。这个临界点就是五分钟。 看上去像一条经验性的法则,实际上五分钟的评估标准是根据投入成本判断的,根据当时的硬件发展水准,在内存中保持 1KB 的数据成本相当于硬盘中存据 400 秒的开销(接近五分钟)。这个法则在 1997 年左右的时候进行过一次回顾,证实了五分钟法则依然有效(硬盘、内存实际上没有质的飞跃),而这次的回顾则是针对 SSD 这个”新的旧硬件”可能带来的影响。
随着闪存时代的来临,五分钟法则一分为二:是把 SSD 当成较慢的内存(extended buffer pool )使用还是当成较快的硬盘(extended disk)使用。小内存页在内存和闪存之间的移动对比大内存页在闪存和磁盘之间的移动。在这个法则首次提出的 20 年之后,在闪存时代,5 分钟法则依然有效,只不过适合更大的内存页(适合 64KB 的页,这个页大小的变化恰恰体现了计算机硬件工艺的发展,以及带宽、延时)。